 Archives
Archives

今回のテーマは日々私が仕事で体験していることに密接に関係しているので、大変興味深く参加させていただきました。「分析力」をはじめとして関連する諸事項について分かりやすいプレゼンから多くを得ました。特に。案内のパンフレットにあったように、多くのビッグデータは非構造化データであることの意味が大変よく分かりました。ここでは、簡単に当日のセミナーのハイライトを報告させていただきます。
プロローグ


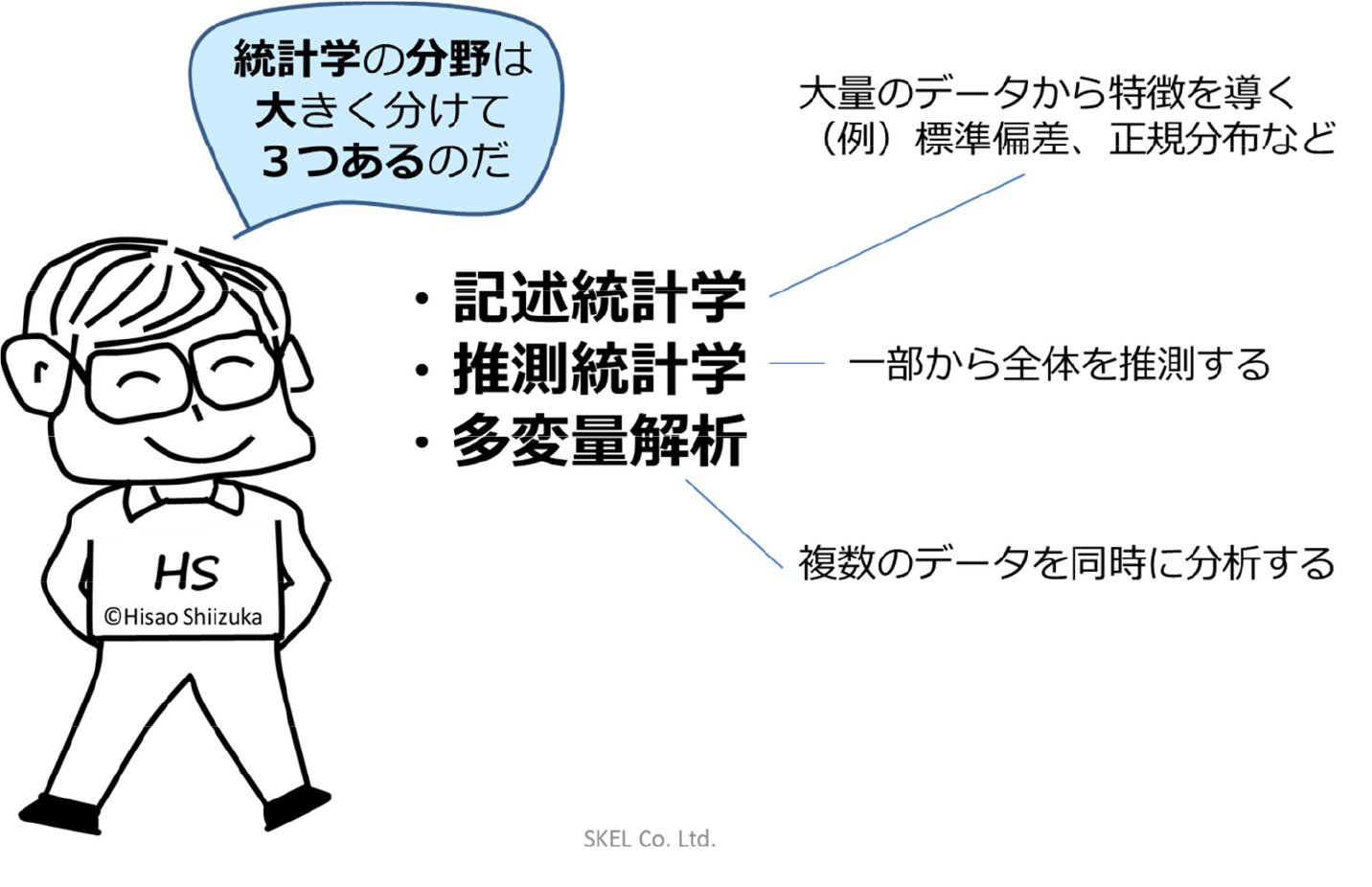
1.統計学の分野は大きく分けると3つある
2.構造化データと非構造化データ

3.定量分析では、「何を解決したいのか」を明確に
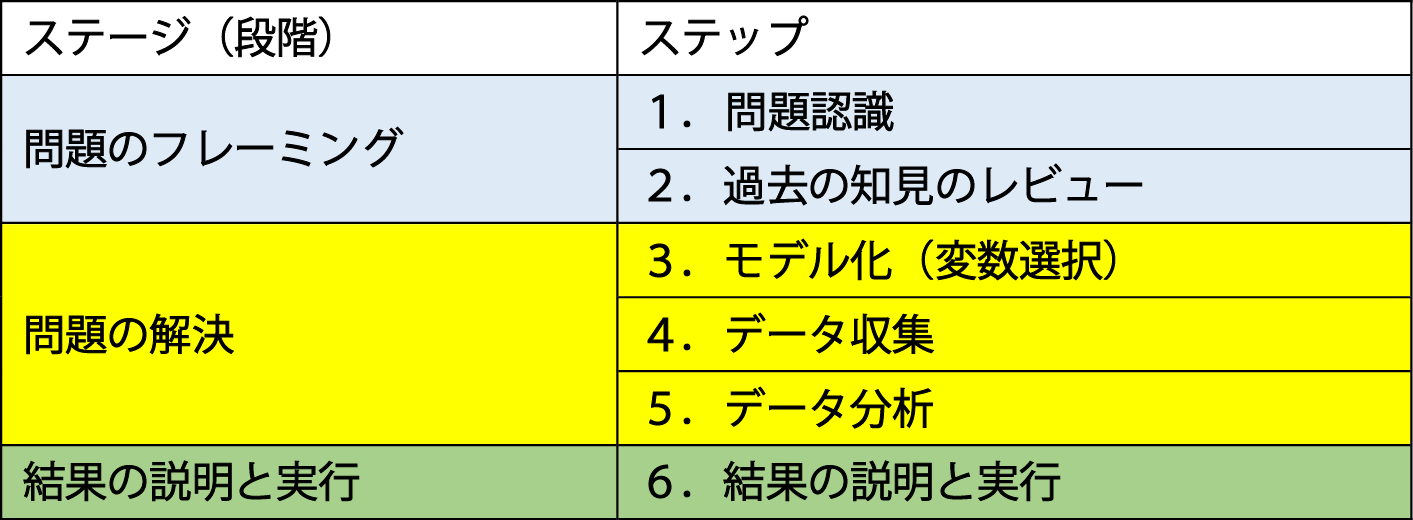
1) 問題認識
踏み出すきっかけは純粋な好奇心である。分析を行うかどうかは勘や直感が決めることが多い。最も重要なのは、「問題は何か」そして「問題解決がなぜ必要かつ重要か」をきちんと理解することである。
特に、分析結果の利害関係者を明らかにし、その関心や期待を評価・コントロールすることが求められる。つまり、「どんな決定がされそうか」、そのためには「どんな問いが必要とされているか」を明確にすることである。
特に、分析結果の利害関係者を明らかにし、その関心や期待を評価・コントロールする ことが求められる。つまり、「どんな決定がされそうか」、そのためには「どんな問いが必 要とされているか」を明確にすることである。
2) 過去の知見のレビュー
その問題に関するこれまでの構造化と概念化をレビューすることで、問題認識ステップの大幅な修正の必要に気づくことが多い。
3) モデル化(変数選択)
ここからは問題解決のステップである。問題解決のステップは定量分析を得意とする専門家(市場調査会社やコンサルタント、大学教授など)に任せることもできる。モデルとは「漫画のようなもの」。現実世界の特徴を意図的に際立たせたものである。そのためには、変数を取捨選択する必要がある。つまり予測・説明しようとしている「従属変数」と、それに影響を与える「独立変数」を仮定するところから始まる。この「モデル化」がないと研究論文(学問)にはならないので、博士論文を書こうとしている人にとってもっとも重要なプロセスとも言えるだろう。椎塚先生はこの部分をかな り強調し、「研究の進め方や論文の書き方が分からない人が多く、それは教える側にも問題がある」と言っていた。

4) データ収集(計測)
ステップ1で選択した変数に数字を当てはめるプロセスである。かつては収集されたデータの大半が数値で示される構造化データであった。ところが、20世紀後半からはテキスト分析にはじまり、音声データや動画データなど、そのままでは数値化できないような、非構造化データが大量に収集され、分析の対象とされるようになった。つまりビッグデータの時代に突入したのである。データサイエンティストは、非構造化データをいかに数値化して分析できる形に処理するかに精通していなければいけなくなった。そして処理されて構造化されたデータを次のステップに進めるのである。
5) データ分析
データに潜んでいる変数間の関係(パターン)をみつけるのが、データ分析である。ここで議題が、「サンプリング」に移った。標本データで観察された関係が母集団においても成り立つかどうかの推定が重要とされるからだ。正規分布がなぜ重要なのか、それをなぜ「確率密度関数」と呼ぶのかなど。しかし「力づく」のビッグデータ時代となり、サンプリング(部分計測)から全体計測に移行したことで、部分から全体を推定することに意味があるのかが問われるようになった。また、因果関係(理由)がわからなくても、相関関係(結果)がわかればよいではないか、という風潮も出てきている。ICT の発達による情報処理能力増大とコスト低減が全体計測とその分析を可能にしたことは言うまでもない。全て揃っているわけではないこと、因果関係がわからないため意思決定の理由を明確に説明できないこと、そして分析者の展望なしには役に立つ結果がでないことによるものだ。リトルデータにも宝の山が眠っていることを忘れてはいけない。
6) 分析結果を伝え実行に移す
問題とその裏に潜むストーリー、モデル、使われたデータ、分析で使用した変数間の関係について説明する。変数間の関係が見えたら、ビジネス課題に関連付けて意味を解釈し、問題解決のための指針を述べることも必要だ。意思決定に使われて初めて分析は意味を持つのである。それに成功したのがナイチンゲールで、失敗したのがメンデル。ナイチンゲールは分析結果の表現方法など、プレゼンテーションも素晴らしかった。
4.量的研究の限界と質的研究方法論
次回につづく…
エピローグ
<報告者より>
第一の対立:構造化データと非構造化データ
第二の対立:サンプリングと全体計測
第三の対立:ビッグデータとリトルデータ
第四の対立:計測できるもの(量的研究)とできないもの(質的研究)
第五の対立:システム思考とデザイン思考
